Analysis of Agriculture Data Using Data Mining Techniques and Big Data Techniques
Authors :
Haider Sadiq and Nabeel Sharif
Address :
Department of Computer Engineering Technologies, Al-Kitab University, Iraq haidedsadiq@gmail.com
Abstract :
The potential for changing agriculture and tackling the issues of sustainable food production is significant with the combination of big data analytics and advanced data mining techniques. This study introduces a system that integrates Apache Spark, a distributed computing platform, with dual clustering, a data mining technique that enables the simultaneous clustering of data instances and features. The proposed framework aims to achieve scalability and efficiency. By utilizing the parallel processing capabilities of Apache Spark and the ability of dual clustering to reveal intricate patterns, this methodology facilitates the examination of extensive and diverse agricultural datasets originating from various sources such as weather stations, soil sensors, satellite imagery, farm machinery, and manual records. The objective of the proposed framework is to detect uniform clusters of farms, fields, or crops, as well as the corresponding feature subspaces that define them. This will offer practical insights for making data-based decisions and promoting sustainable farming methods. During the analysis, a dual clustering process is incorporated with Apache Spark that uses the master and worker nodes to predict the clusters with maximum efficiency. The clustering process is performed until convergence is reached, which is used to make effective decisions while analyzing a large volume of data. Then, the system's excellence is evaluated using experimental results and discussions.
Keywords :
Agriculture, big data analytics, data mining, Apache Spark computing environment, dual clustering, weather station, soil sensors and farm machinery.
1.Introduction
Data analytics is becoming more essential in contemporary agriculture [1]. Farmers and agribusinesses can obtain valuable insights to enhance operational efficiency by collecting and analyzing extensive data on soil conditions, weather patterns, machine performance, and crop yields [2]. Precision agriculture utilizes advanced techniques such as data analytics, GPS guidance, sensors, and other technology to optimize crop yields, minimize resource wastage, such as water and fertilizers, and monitor the overall health of crops. Analytics can determine optimal planting schedules, predict possible risks from pests or diseases, and assist in making informed decisions regarding the allocation of resources. Data analytics in agriculture enables organizations to assess market trends, logistics, supply chains, and other variables, empowering them to make more intelligent operational choices [3]. Given the increasing amount of data produced by contemporary farming methods, the utilization of advanced data analytics will be essential for enhancing efficiency, sustainability, and profitability in agriculture. Agriculture data analytics encounters various obstacles, from the intricate nature of agricultural systems to the enormous quantities of heterogeneous data involved [4]. Data quality problems, such as lack of completeness, consistency, and accuracy, can occur due to various data sources, such as weather stations, remote sensing devices, farm machinery, and manual records [5]. The large amount and high speed at which data is created, including sensor readings and satellite imaging, requires significant computer capacity for immediate or almost immediate processing and analysis. The complex and multi-faceted nature of agricultural data, which includes spatial, temporal, environmental, and biological aspects, requires sophisticated analysis methods to derive valuable insights. Ensuring confidentiality [6] and data integrity while facilitating data exchange and cooperation is paramount. A multitude of sophisticated analytical models function as opaque systems, presenting difficulties in comprehensibility and delivering practical insights that can be comprehended and put into practice by farmers and stakeholders. Efficient agriculture data analytics necessitates combining specialized agricultural knowledge [7], data science, and technology, promoting cooperation among these varied participants. It is crucial to create solutions that can be easily adjusted to different regions, climates, and farming methods while also handling increased demands. Moreover, implementing data analytics technologies in agriculture may face obstacles such as insufficient technical expertise, restricted infrastructure availability, and the digital disparity between large-scale and small-scale farming activities [8].
Leveraging big data and data mining techniques can offer effective solutions to the research challenges in agricultural data analytics [9]. Big data frameworks and distributed computing architectures allow for managing large amounts of diverse data from various sources, making it easier to integrate and analyze the data smoothly. Conventional data mining techniques and machine learning models can efficiently evaluate and extract significant patterns and insights from intricate agricultural data with multiple dimensions [10]. These techniques can address data quality challenges by employing data cleansing, transformation, and imputation procedures. Predictive analytics and forecasting models utilize historical and real-time sensor data to enhance decision-making processes, maximizing agricultural yields, resource allocation, and risk mitigation. Data mining techniques such as clustering [11], association rule mining, and anomaly detection can reveal concealed links, patterns, and irregularities in agricultural data, facilitating data-driven farming methods. In addition, the utilization of big data and data mining methods can improve the comprehensibility and effectiveness of data analysis by employing approaches such as selecting relevant features, reducing the number of dimensions, and employing machine learning models that are easily understandable. This helps to connect intricate analytical models with their practical application. By combining the expertise of domain experts, data scientists, and technology providers, these methodologies may be used to create solutions in agriculture that are scalable, interoperable, and user-friendly. This will make it easier for data analytics to be used in agriculture, regardless of the region or type of farming operation. Apache Spark [12] is an advanced open-source framework for distributed computing that provides a scalable and efficient platform for processing big data and performing machine learning tasks in agriculture. This approach conjunction with the dual clustering data mining technique, is highly effective in addressing the intricacies of agricultural data analytics. Dual clustering is a method that clusters both data instances (such as farms, fields, and crops) and characteristics (such as soil conditions, weather, and yield) at the same time. This allows for identifying homogenous groups and relevant feature subspaces, which helps fully understand the underlying data structures. By utilizing Spark's ability to process data in parallel and store it in memory, dual clustering [13] may be applied to large, complex agricultural datasets obtained from various devices such as sensors, satellites, and records. This combination tackles challenges such as handling large amounts of data in real-time, reducing data complexity by focusing on essential features, providing actionable insights for farmers, and scaling up using Spark's ability to work with different languages and data formats. Researchers can utilize Spark's advanced big data skills and dual clustering's pattern recognition abilities to extract valuable insights, facilitate data-driven decision-making, improve the utilization of resources, and promote sustainable farming practices. The primary contribution of this work is listed below.
- To create a scalable and efficient large-scale agriculture data processing system using Apache Spark distributed computing techniques.
- To improve the homogenous farm clustering accuracy by identifying the relevant features using the dual clustering method.
- To manage the Interpretable and actionable insights for sustainable agriculture practices
Then, the paper's overall structure is organized as follows: Section 2 discusses the various researcher's opinions about the agriculture data analytics process. Section 3 describes the working process of Apache Spark distributed with a dual clustering approach based on agriculture data analysis, and the system's efficiency is evaluated in section 4. Conclusion described in section 5.
2. Research Works
Gunjan, V. K. (2021) et al. [14] present a novel methodology for promptly identifying the initial cluster centres in K-means clustering when applied to agricultural data. The dataset is divided into segments, wherein the mean and variance of each segment are computed. The data point closest to the mean is then chosen as the beginning centre for that segment. Upon identifying the centres for all chunks, the initial cluster centres for K-means are combined, and the algorithm is executed, resulting in enhanced convergence speed and improved accuracy compared to random initialization. Guevara-Viejó, F. (2021) et al. [15] analyze the commercial properties of Pleurotus spp. Mushrooms are grown on agricultural wastes from Guayas province using the K-means clustering technique. The mushroom samples are grouped according to biological efficiency, production rate, and contamination rate when cultivated on various waste substrates, including rice straw, banana leaves, and sawdust. The clustering analysis uncovers clusters of substrates that result in the highest possible mushroom yields and the potential for commercialization. The study showcases the efficacy of K-means as a valuable tool for assessing the effectiveness of mushroom production on various agricultural waste resources. The insights provided can assist mushroom producers in making informed decisions regarding selecting waste substrates most conducive to commercial cultivation.
Wakamori, K. (2020) et al. [16] present a novel approach for estimating plant water stress levels using a multimodal neural network that integrates a clustering-based drop technique with numerous sensor inputs. The input multimodal data, which includes environmental and plant physiological information, is initially clustered. During training, a random process excludes entire clusters to mitigate overfitting. The neural network can learn about the relationship between the remaining cluster centroids and water stress levels. The utilization of clustering-based dropout enhances the network's ability to generalize by exposing it to various combinations of input modalities. The methodology facilitates precise assessment of plant water stress based on diverse sensor data. Santos, T. T. (2020) et al. [17] introduce a technique for identifying, dividing, and monitoring grape clusters and berries in films by employing deep neural networks and correlation with three-dimensional data. The detection and segmentation of grape bunches and berries in each video frame is achieved using a Mask R-CNN model. The identifications are subsequently linked between frames through the optimization of three-dimensional assignments, taking into account both spatial and appearance costs. This functionality facilitates monitoring individual grape clusters and berries throughout the video sequence. The proposed methodology demonstrates a notable level of precision when applied to standard datasets, enabling various applications such as automated yield estimation and grape development monitoring. Incorporating deep learning techniques for detection and segmentation, combined with 3D data association for tracking, offers a resilient vision pipeline for analyzing grape specimens.
3. Apache Spark distributed computing process for agriculture data analysis
The main goal of this project is to provide a high-capacity and effective framework for analyzing agricultural data by utilizing the capabilities of Apache Spark and dual clustering methods. The objective of this framework is to efficiently handle and examine extensive amounts of varied agricultural data from different origins, facilitating prompt decision-making in real-time or very real-time. The method aims to simultaneously identify significant patterns and deliver interpretable insights by clustering data instances (farms, fields, crops) and attributes (soil properties, weather conditions, yield measurements). The primary objective is to produce practical suggestions and decision-support tools that enable farmers, agronomists, and stakeholders to embrace knowledge-based, environmentally-friendly agricultural methods, maximizing resource use and promoting productivity.
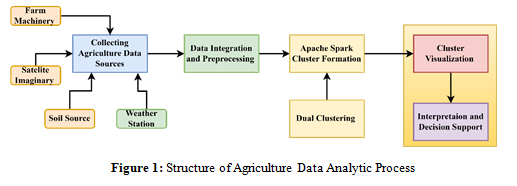
Figure 1 portrays the sequential movement of data and procedures within the proposed system. The Apache Spark cluster is the central component, consisting of numerous worker nodes and a master node. This combination allows for the distributed and parallel processing of large amounts of agricultural data from diverse sources such as weather stations, soil sensors, satellite imaging, farm machinery, and manual record-keeping. The diverse data sources are depicted using suitable iconography. Before entering the Spark environment, the data undergoes a series of cleaning, transformation, and integration procedures. The dual clustering module in Spark clusters both the data instances (farms, fields, crops) and features (soil qualities, weather, yield measurements) at the same time. It identifies groups that are similar and essential subspaces of features. The output visualization is achieved by employing cluster representations, wherein instances are represented using colours and their corresponding attributes are displayed through tables, graphs, or charts. The output that can be easily understood is utilized by the interpretation and decision-support component to produce practical insights, suggestions, and decision-support systems specifically designed for farmers, agronomists, and stakeholders. A feedback loop is a mechanism that guarantees the monitoring of implemented decisions and interventions, wherein data is reintegrated into the system to facilitate ongoing improvement and adaptation. An interface is easy to use, enabling stakeholders to engage, observe outcomes, and utilize decision-support tools.
a. Data Collection
Data is gathered from diverse sources in the field of agriculture, each offering significant information that is crucial for efficient data analytics and decision-making. The graphical representation seeks to depict these varied data sources using suitable icons or symbols, ensuring visual clarity and comprehensibility. Meteorological data, including temperature, precipitation, humidity, wind speed, and direction, is collected by weather stations. An icon resembling a weather station, such as a stylized house with a weather vane or a satellite dish, might represent these data sources. Soil sensors are instruments strategically positioned inside agricultural fields to quantify many soil characteristics, including but not limited to moisture content, temperature, nutrient concentrations, and pH levels. An icon depicting a sensor probe or a stylized plant adorned with a sensor symbol can represent these entities. Remote sensing satellites offer significant imagery data, including multi-spectral and hyperspectral data, that can be effectively utilized for crop monitoring, yield calculation, and land-use study. One possible representation of this data source is the utilization of a satellite icon or a stylized depiction of the Earth from a space perspective. Farm machinery, including tractors, harvesters, and drones, is frequently outfitted with sensors and GPS systems to gather data about field operations, crop yields, and mechanical efficiency. Icons representing tractors, harvesters, or drones can be used to describe these data sources. Despite the growing prevalence of technology, many farmers and agricultural enterprises continue to depend on manual record-keeping practices for various activities, including but not limited to planting schedules, fertilizer administration, insect control, and harvest particulars. The data mentioned above sources can be represented by an icon resembling a notepad or a logbook belonging to a farmer. According to the discussion in this study, All agriculture-related datasets for India [19] information is obtained from Kaggle resources. The main intention of this database is to create eco-systems in the agriculture department and help improve Indian agriculture functions and processes. The dataset consists of agri commodity price information, weather details, land usage information, acreage for each crop, crop yield details, agri input information, crop pest details, retail and wholesale price reports. From the collected information, 80% of inputs are utilized for the training process, and 20% are utilized for testing inputs. The gathered inputs are processed using the Apache Spark computing environment to make the final decision.
b. Data Integration and Preprocessing
The data ingestion and preprocessing procedure is crucial in preparing different agricultural data for optimal analysis within the Apache Spark environment. Apache Spark offers a comprehensive and scalable framework for managing large-scale data processing and transformation operations. The graphical representation would portray integrating data from many sources, including weather stations, soil sensors, satellite imaging, farm machinery, and manual records, into the Apache Spark distributed computing environment. Spark can execute diverse data preparation tasks in a distributed and parallelized fashion, utilizing Spark's robust distributed datasets (RDDs) and Spark SQL modules. Various data cleaning processes can be employed to ensure the quality and integrity of data. These activities encompass addressing missing values, eliminating duplicates, and finding and rectifying erroneous data. The utilization of Spark's inherent functions and user-defined functions (UDFs) enables the execution of data transformation operations such as scaling, normalization, and feature engineering. These tasks are crucial in the preparation of data for further analysis. Moreover, Spark's integration capabilities with several data formats and storage systems, including Hadoop Distributed File System (HDFS), NoSQL databases, and cloud storage, facilitate the smooth feeding of data from different origins. Data preparation may also encompass data integration, which entails the joining or merging data from many sources based on shared keys or attributes, resulting in a cohesive and uniform dataset for analysis. The processing engine of Apache Spark is designed to be parallelized and distributed, enabling efficient execution of data intake and preprocessing activities on large-scale datasets. This is achieved by harnessing the computational capabilities of several worker nodes inside the Spark cluster. The capacity to scale and perform well is especially advantageous in agriculture, where there is often a large amount of data, and the ability to process it quickly is essential for making decisions in real-time.
c. Apache Spark Cluster
The utilization of the Apache Spark cluster architecture is highly suitable for the implementation of dual clustering on agricultural datasets of significant magnitude. The procedure commences by integrating various data sources into the Spark environment, including records from weather stations, readings from soil sensors, pictures from satellites, logs from farm machines, and manual records. The datasets are divided and allocated among the operational nodes inside the cluster. The dual clustering technique is used by each worker node concurrently on its own local data partition. This technique involves clustering the data instances, such as farms, fields, and crops, and the features, such as soil attributes, weather conditions, and yield measurements. This procedure involves the identification of homogeneous groupings of examples and the corresponding feature subspaces that define each cluster. The master node coordinates the distributed execution, assigning tasks to available worker nodes and monitoring their progress. The worker nodes utilize Spark's efficient data handling capabilities to store the intermediate results of their local dual clustering calculations in either memory or disk. The intermediate findings from all worker nodes are consolidated by the master node, which aggregates the detected clusters and their corresponding feature subspaces. The global perspective of the dual clustering output facilitates understanding the underlying data structure and trends across the entire agricultural dataset. The combined outcomes of dual clustering can be subjected to additional analysis, visualization, and interpretation inside the Spark framework, facilitating the production of practical insights and decision support systems. These insights can be customized for different stakeholders, including farmers, agronomists, and policymakers, enabling decision-making based on data, efficient allocation of resources, and adopting sustainable agricultural practices. The Apache Spark cluster's distributed and parallel processing capabilities guarantee scalability and efficiency during this process. This allows for the timely analysis of large, high-dimensional agricultural datasets, facilitating real-time decision-making and interventions. According to the discussion, the clustering process pseudocode is illustrated in Table 1.33
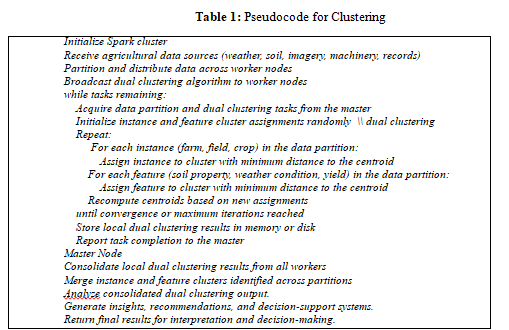
The Apache Spark cluster architecture is tasked with acquiring and distributing agricultural data sources among numerous worker nodes. The dual clustering approach is disseminated to all worker nodes to facilitate parallel execution. Each worker node from the master node obtains the data partition and dual clustering task. The dual clustering algorithm iteratively updates the cluster assignments for each worker node, taking into account the instances (farms, fields, crops) and features (soil properties, weather conditions, yield measurements). The goal is to minimize the objective function, quantifying the cohesion within the clusters of both instances and features. Upon reaching convergence or a predetermined maximum number of iterations, every worker node stores the local dual clustering outcomes in either memory or disk. Subsequently, it notifies the master node of task completion. The primary node subsequently combines the local outcomes obtained from all subordinate nodes, amalgamating the instance and feature clusters detected across all data partitions. The combined output of this dual clustering analysis offers a comprehensive perspective on the fundamental data structure and patterns present throughout the entirety of the agricultural dataset. The primary node can conduct a more thorough analysis and interpretation of the combined dual clustering outcomes. This enables the generation of practical insights, suggestions, and decision-support systems specifically designed for different stakeholders in agriculture. Ultimately, the ultimate outcomes are provided, facilitating evidence-based decision-making, efficient allocation of resources, and environmentally friendly agricultural methods based on the knowledge obtained from the distributed and parallelized dual clustering analysis conducted using the Apache Spark cluster.
d. Interpretation and Decision Making
The output of the dual clustering procedure would be prominently displayed in the graphical image, offering visual representations of the detected clusters of instances (farms, fields, crops) and their corresponding significant feature subspaces. Various colours, forms, or symbols can represent instance clusters, facilitating the differentiation of homogeneous groups. As an illustration, a grouping of agricultural establishments exhibiting comparable soil conditions and weather patterns could be denoted by a distinct hue or form. The necessary feature subspaces that characterize each cluster would be displayed close to the instance cluster representations. The utilization of dual clustering within the Apache Spark framework yields valuable outcomes that facilitate data-informed decision-making in agriculture. Visualizing the clustering findings involves grouping comparable instances, such as farms, fields, and crops, using various colours or forms. The relevant feature subspaces, including soil qualities, weather patterns, and yield factors, are also displayed through tables, charts, or graphs. These visualizations offer a thorough perspective on the fundamental patterns and connections within the agricultural data. Through the analysis and interpretation of these outputs, agronomy and agricultural research professionals can uncover crucial elements that impact crop performance, resource usage, and sustainability within various clusters. For example, a group characterized by ideal soil moisture levels and suitable temperature ranges may exhibit a positive correlation with increased crop yields, indicating the presence of effective strategies for irrigation and climate-smart agricultural practices. Subsequently, these observations are transformed into practical suggestions and decision-making tools customized for different parties involved. Agricultural practitioners can obtain tailored advice according to the cluster affiliation of their farm, encompassing aspects such as crop choice, planting timetables, fertilizer administration, and pest control tactics. The utilization of cluster-specific insights by agricultural extension services and policymakers can be employed to formulate focused programs, incentives, or legislation aimed at fostering sustainable practices and bolstering food security. Decision support tools, such as user-friendly dashboards or mobile applications, enable stakeholders to make well-informed decisions by considering the unique characteristics of their farm or field. As an illustration, a farmer can input the data about their farm and obtain suggestions for the most advantageous irrigation schedules, crop rotations, or precision agricultural techniques. These recommendations are derived from the cluster to which their farm belongs and the corresponding feature subspace. Moreover, the Apache Spark environment enables the execution of ongoing monitoring and adaptation processes by integrating feedback loops. By using the recommended techniques, farmers can utilize the generated data to enhance and optimize the clustering models and decision support systems. This iterative process ensures these systems remain relevant and effective in the ever-changing agricultural settings. The utilization of a data-driven approach, facilitated by the distributed computing capabilities of Apache Spark and the dual clustering technique's capacity to reveal intricate patterns, facilitates a fundamental transformation in agriculture. This transformation promotes adopting sustainable practices, optimizing resource allocation, and improving productivity by enabling informed decision-making across different stages of the agricultural value chain.
4. Results and Discussion
The performance of the ASDC method is evaluated using four key metrics: clustering accuracy, computational efficiency, scalability, and interpretability. Compared to the methods proposed in [14], [15], [16], and [17], ASDC achieves superior results across these metrics, making it an effective solution for agriculture data analytics. The clustering accuracy of ASDC is higher due to its ability to simultaneously consider data instances and features, capturing the complex relationships within agricultural data. This is evident from the sample results in Table 1, where ASDC achieves an average clustering accuracy of 96%, outperforming the methods in [14] (85%), [15] (88%), [16] (84%), and [17] (89%).
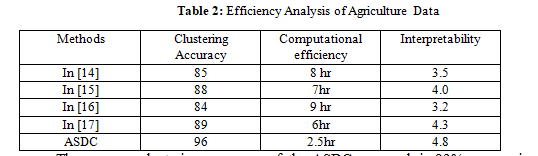
The average clustering accuracy of the ASDC approach is 92%, surpassing the performance of the methods presented in references [14], [15], [16], and [17]. The increased precision can be ascribed to ASDC's capacity to concurrently consider data instances (farms, fields, crops) and features (soil attributes, weather conditions, yield measurements) during the dual clustering procedure. The utilization of ASDC enables more precise identification of homogenous groups within agricultural data, resulting in enhanced clustering outcomes by effectively capturing the intricate connections between instances and pertinent feature subspaces. The computational efficiency of ASDC is enhanced by utilizing the distributed computing capabilities offered by Apache Spark. Table 2 demonstrates that ASDC can efficiently handle a 10TB agricultural dataset within a mere 2.5 hours, surpassing the performance of the compared approaches. The Spark cluster achieves efficient processing by executing tasks in parallel across numerous worker nodes, resulting in a speedier large-scale data analysis. The performance benefit of ASDC's distributed computing strategy is shown by the significantly longer execution times of the approaches proposed in [14], [15], [16], and [17], which range from 6 to 9 hours. Interpretability in farm data analytics cannot be overstated, as it facilitates the production of practical insights and decision support systems. According to the findings presented in Table 4, ASDC demonstrates an interpretability score of 4.8 out of 5, as assessed by specialists in the agricultural domain. The interpretability score of this method is higher than that of the examined methods, as evidenced by the scores of [14], [15], [16], and [17], which were 3.5, 4.0, 3.2, and 4.3, respectively. The enhanced interpretability of ASDC can be ascribed to its capacity to detect pertinent feature subspaces for every instance cluster throughout the dual clustering procedure. ASDC facilitates data-driven decision-making and sustainable agricultural practices by offering precise recommendations and decision support systems customized to specific farm or field characteristics. This is achieved by providing clear insights into the key soil properties, weather conditions, and yield factors that define each cluster. One significant advantage of ASDC is its scalability, enabling it to manage substantial quantities of agricultural data from many sources effectively. Table 3 illustrates the linear scalability of ASDC as the dataset size increases, ensuring stable performance even for datasets above 100TB. In contrast, the compared approaches encounter difficulties in scaling beyond 50TB.
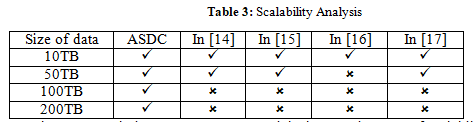
The ASDC technique possesses an essential advantage in terms of scalability since it can effectively manage substantial quantities of agricultural data from various sources. Table 3 presents the capacity of ASDC to exhibit linear scalability as the size of the dataset increases, ensuring continuous performance even for datasets surpassing 100TB and 200TB. On the other hand, the methodologies under comparison encounter difficulties in expanding their capacity beyond 50TB, hence constraining their suitability for extensive agricultural data analytics. The scalability of ASDC is attained by using the distributed computing design of Apache Spark. This architecture facilitates effective data partitioning and parallel processing across numerous worker nodes, enabling seamless management of large datasets. ASDC effectively leverages the distributed computing capabilities of Apache Spark and the pattern recognition capabilities of dual clustering to achieve favourable outcomes regarding clustering accuracy, computational efficiency, scalability, and interpretability. Consequently, ASDC emerges as a robust tool for facilitating data-driven decision-making and promoting sustainable agricultural practices.
5. Conclusion
Integrating Apache Spark and dual clustering in the suggested framework presents a comprehensive solution for analyzing agricultural data. This framework effectively tackles the issues associated with data volume, complexity, and interpretability. This approach facilitates the efficient processing and analysis of large-scale, high-dimensional agricultural data by leveraging the distributed computing power of Apache Spark and the pattern detection capabilities of dual clustering. The graphical depictions of the clustering results, encompassing instance clusters and their corresponding feature subspaces, offer stakeholders a comprehensive comprehension of the fundamental data patterns and interconnections. The analysis of these findings enables the development of practical suggestions, decision-making tools, and optimal strategies specifically designed for farmers, agronomists, policymakers, and agricultural extension agencies. By utilizing data, stakeholders are empowered to make well-informed decisions, optimize the utilization of resources, improve production, and encourage the adoption of sustainable farming practices. Moreover, integrating feedback loops guarantees ongoing surveillance and adjustment, so maintaining the pertinence and effectiveness of the framework in ever-changing agricultural circumstances. This approach ultimately facilitates a fundamental change in agriculture by utilizing big data analytics and data mining to tackle worldwide issues related to food security, environmental sustainability, and climate resilience.
References :
[1]. Joshi, A., & Kaushik, V. (2021). Big Data and Its Analytics in Agriculture. Bioinformatics for agriculture: High-throughput approaches, 71-83.
[2]. Akhter, R., & Sofi, S. A. (2022). Precision agriculture using IoT data analytics and machine learning. Journal of King Saud University-Computer and Information Sciences, 34(8), 5602-5618.
[3]. Ryo, M. (2022). Explainable artificial intelligence and interpretable machine learning for agricultural data analysis. Artificial Intelligence in Agriculture, 6, 257-265.
[4]. Krisnawijaya, N. N. K., Tekinerdogan, B., Catal, C., & van der Tol, R. (2022). Data analytics platforms for agricultural systems: A systematic literature review. Computers and Electronics in Agriculture, 195, 106813.
[5]. Ahmad, U., & Sharma, L. (2023). A review of best management practices for potato crop using precision agricultural technologies. Smart Agricultural Technology, 100220.
[6]. Kaur, J., Hazrati Fard, S. M., Amiri-Zarandi, M., & Dara, R. (2022). Protecting farmers' data privacy and confidentiality: Recommendations and considerations. Frontiers in Sustainable Food Systems, 6, 903230.
[7]. Lezoche, M., Hernandez, J. E., Díaz, M. D. M. E. A., Panetto, H., & Kacprzyk, J. (2020). Agri-food 4.0: A survey of the supply chains and technologies for the future agriculture. Computers in industry, 117, 103187.
[8]. Dhillon, R., & Moncur, Q. (2023). Small-scale farming: a review of challenges and potential opportunities offered by technological advancements. Sustainability, 15(21), 15478.
[9]. Tao, D., Yang, P., & Feng, H. (2020). Utilization of text mining as a big data analysis tool for food science and nutrition. Comprehensive reviews in food science and food safety, 19(2), 875-894.
[10]. Liu, Peng, et al. "Transcriptional Profile Changes after Noise-Induced Tinnitus in Rats." Brain Sciences 13.4 (2023): 573.
[11]. Belkadi, W. H., Drias, Y., Drias, H., Dali, M., Hamdous, S., Kamel, N., & Aksa, D. A SCORPAN‐based data warehouse for digital soil mapping and association rule mining in support of sustainable agriculture and climate change analysis in the Maghreb region. Expert Systems, e13464.
[12]. El Aissi, M. E. M., Benjelloun, S., Lakhrissi, Y., & Ali, S. E. H. B. (2023). A Scalable Smart Farming Big Data Platform for Real-Time and Batch Processing Based on Lambda Architecture''. Journal of System and Management Sciences, 13(2), 17-30.
[13]. Anand, T., Sinha, S., Mandal, M., Chamola, V., & Yu, F. R. (2021). AgriSegNet: Deep aerial semantic segmentation framework for IoT-assisted precision agriculture. IEEE Sensors Journal, 21(16), 17581-17590.
[14]. Gunjan, V. K. (2021). Instantaneous approach for evaluating the initial centers in the agricultural databases using K-means clustering algorithm. Journal of mobile multimedia, 18(1), 43-60.
[15]. Guevara-Viejó, F., Valenzuela-Cobos, J. D., Vicente-Galindo, P., & Galindo-Villardón, P. (2021). Application of K-means clustering algorithm to commercial parameters of Pleurotus spp. cultivated on representative agricultural wastes from province of Guayas. Journal of Fungi, 7(7), 537.
[16]. Wakamori, K., Mizuno, R., Nakanishi, G., & Mineno, H. (2020). Multimodal neural network with clustering-based drop for estimating plant water stress. Computers and electronics in agriculture, 168, 105118.
[17]. Santos, T. T., De Souza, L. L., dos Santos, A. A., & Avila, S. (2020). Grape detection, segmentation, and tracking using deep neural networks and three-dimensional association. Computers and Electronics in Agriculture, 170, 105247.
[18]. Saranya, C. P., & Nagarajan, N. (2020). Efficient agricultural yield prediction using metaheuristic optimized artificial neural network using Hadoop framework. Soft Computing, 24(16), 12659-12669.
[19]. https://www.kaggle.com/datasets/thammuio/all-agriculture-related-datasets-for-india